
Table of contents

Do you want to increase sales and build even better relationships with your customers?
Word2Vec is a Machine Learning method of building a language model based on Deep Learning ideas; however, a neural network that is used here is rather shallow (consists of only one hidden layer).
This series of articles’ main goal is to convince the reader that natural language processing is not that hard – word2vec is sort of “Hello world” in the NLP field. However, it requires a bit more work than writing a line of code.
- How word2vec works and where the idea and concept came from.
- How to make a simplified version of word2vec yourself.
- How to use simple word2vec for exciting things.
One last thing before we start
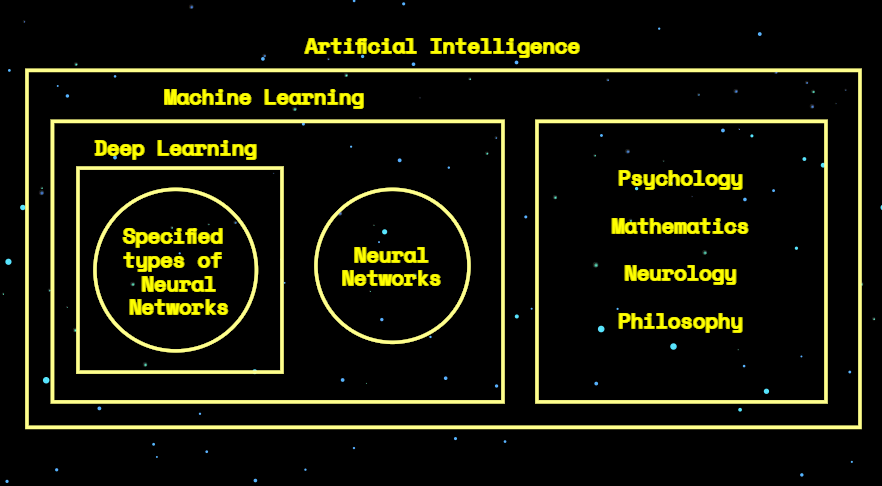
For the sake of the following article, it’s not that important for you to understand the difference between Artificial Intelligence, Machine Learning and Deep Learning. However, these terms are often mixed and used as synonyms, which is mostly wrong:
- Deep learning deals with a particular type of neural network (deep neural networks: with lots of layers, or shallow but with many inputs and dependencies between nodes).
- Deep learning as a field is part of the machine learning field.
- Machine learning is part of the artificial intelligence field.
As I wrote above, we are about to use the machine learning method of building a language model based on deep learning ideas.
Quick historical recap
The first wave of Machine Learning hype occurred between 2005 and 2012. The next boom is sometimes called the Deep Learning Revolution and started in 2012. Another important period is the invention of Word2Vec (and its clones: Doc2Vec, Nodes2Vec), which took place from 2013 – 2015. The most recent wave includes the invention of BERT (and also GPT, T5). This period started in 2017, and we are still in it.
Distributional Hypothesis
Word2Vec is a natural language processing (NLP) technique backed with one thesis, popularized by John Rupert Firth in the late ’50s. It says that every word is characterized, and at some point defined, by other words that appear nearby.
In turn, Firth based his theory on Zellig Sabbettai Harris’s idea from 1954, that “Words that occur in the same contexts tend to have similar meanings.” When you give it a second thought, it’s surprisingly accurate. Distributional Hypothesis is the basis for statistical semantics and is gaining a lot of attention in cognitive science and machine learning, although its origins are in linguistics.
Word collocations in text corpus: the basis of computational semantics
The more often word ‘A’ appear in the context of other certain words (e.g. ‘B’, ‘C’, ‘D’, ‘E’), the closer they all are in meaning. The context, is a matter of agreement. It can be the same sentence, paragraph, or—more likely, speaking of NLP—the same frame we use to analyze the text corpus. This is our case.
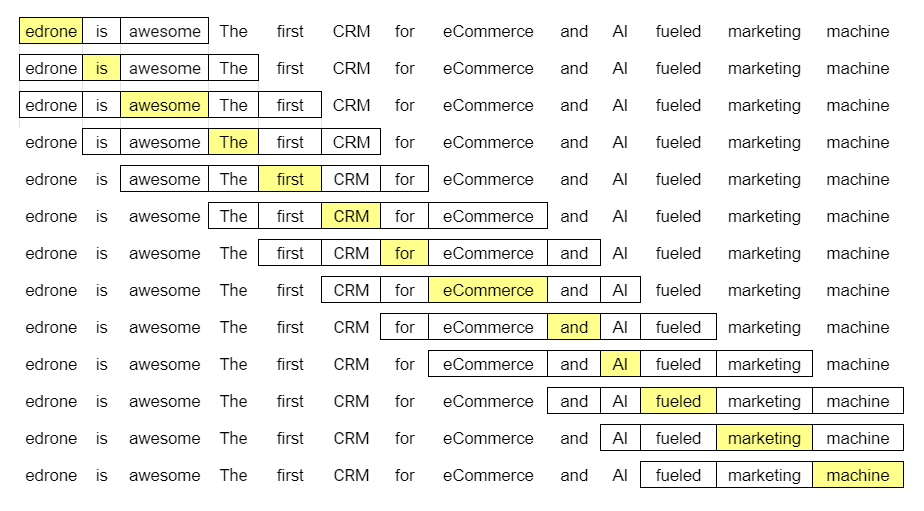
As you probably correctly assume, the bigger the text, the more precise prediction we can perform, and you are exactly right. The size of the frame, however, is a matter of the analyst’s choice. In this case, bigger doesn’t necessarily equal better.
Where should we start? First, we need to make the corpus understandable to computers. Word2vec’s name is a bit self-explanatory – we need to translate the words in a text into vectors. But how do we do it exactly?
Preprocessing
Examples are always the best, so let’s show the steps on this little tiny corpus.
We are about to use Python – an especially handy programming language – while dealing with Machine Learning. If you’re proficient with Python, you surely have an environment prepared and your favorite code editor handy.
If not – don’t worry. It comes with just a few easy steps. I used Spyder as an integrated development environment. After that, you can copy/paste the code presented and test the process yourself.
What’s more, don’t bother if lines of code look like arcane magic. An understanding of the process behind it is not necessary for word2vec comprehension. Simply focus on the output 😉
Let’s create a corpus!
It stands for two simple sentences:
edrone is awesome. The first CRM for e-commerce and AI fueled marketing machine.
Code:
tiny_corpus = ['edrone is awesome',
'The first CRM for e-commerce and AI fueled marketing machine']
print(tiny_corpus,'n')Output:
['edrone is awesome',
'The first CRM for e-commerce and AI fueled marketing machine'] Lowercase and uppercase matter, so let’s make every letter equal (and display to show stages of the tokenization):
Code:
# LOWER CASE
tiny_corpus_lowered = [sentence.lower() for sentence in tiny_corpus]
print(tiny_corpus_lowered,'n')Output:
['edrone is awesome',
'the first crm for e-commerce and ai fueled marketing machine'] Now we cut expressions into single words.
# TOKENIZATION
tiny_corpus_lowered_tokenized = [sentence.split() for sentence in tiny_corpus_lowered]
print(tiny_corpus_lowered_tokenized,'n')[['edrone', 'is', 'awesome'],
['the', 'first', 'crm', 'for', 'e-commerce', 'and', 'ai', 'fueled', 'marketing', 'machine']]At this moment, preprocessing is almost done. Let’s build a dictionary for our tiny corpus. To do so, we create a list of original words, now in alphabetical order, again as a 1-dimensional list, because, as you noticed, the list of sentences has changed into a 2-dimensional list of words (matrix, a.k.a., tensor of order two), which is basically an array.
# DICTIONARY
words = [word for sentence in tiny_corpus_lowered_tokenized for word in sentence]
print(sorted(words),'n')
unique_words = list(set(words))['ai', 'and', 'awesome', 'crm', 'e-commerce', 'edrone',
'first', 'for', 'fueled', 'is', 'machine', 'marketing', 'the'] Let’s create a dictionary, which finalizes the preprocessing stage!
# ASIGN TO DICTIONARY
id2word = {nr: word for nr, word in enumerate(unique_words)}
print(id2word,'n')
word2id = {word: id for id, word in id2word.items()}
print(word2id,'n'){0: 'is', 1: 'ai', 2: 'first', 3: 'e-commerce', 4: 'the',
5: 'fueled', 6: 'machine', 7: 'for', 8: 'awesome',
9: 'and', 10: 'marketing', 11: 'crm', 12: 'edrone'}
{'is': 0, 'ai': 1, 'first': 2, 'e-commerce': 3, 'the': 4,
'fueled': 5, 'machine': 6, 'for': 7, 'awesome': 8,
'and': 9, 'marketing': 10, 'crm': 11, 'edrone': 12} One-Hot Encoding
The process of turning words into vectors is almost done. Now, we assign a vector to every word on our list. Let’s do it and then discuss the result.
# ONE HOT ENCODING
from pprint import pprint
import numpy as np
num_word = len(unique_words)
word2one_hot = dict()
for i in range(num_word):
zero_vec = np.zeros(num_word)
zero_vec[i] = 1
word2one_hot[id2word[i]] = list(zero_vec)
# RESULT
pprint(word2one_hot)And… we are done!
{'ai':
[0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
'and':
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0],
'awesome':
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0],
'crm':
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0],
'e-commerce':
[0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
'edrone':
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0],
'first':
[0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
'for':
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0],
'fueled':
[0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
'is':
[1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
'machine':
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
'marketing':
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0],
'the':
[0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]}As you can see, each original word has its own vector. These vectors are not like the ones you may recall from physics classes. They make no physical sense, since each is embedded in 13-dimensional space, making them impossible to imagine. Luckily, there is no need to do so.
- Each dimension stands for another word in our text.
- Each vector consists of zeros and a single ‘one’.
- Each one appears in another position in our dictionary.
If our text consisted of 100 original words, each vector would be made of 99 zeros and a single ‘1.0’, each in a different position. This convention allows words to be relatively easily processed. How are vectors processed? You will learn in part no. 2!
A whole code for your usage:
tiny_corpus = ['edrone is awesome',
'The first CRM for e-commerce and AI fueled marketing machine']
print(tiny_corpus,'n')
# LOWER CASE
tiny_corpus_lowered = [sentence.lower() for sentence in tiny_corpus]
print(tiny_corpus_lowered,'n')
# TOKENIZATION
tiny_corpus_lowered_tokenized = [sentence.split() for sentence in tiny_corpus_lowered]
print(tiny_corpus_lowered_tokenized,'n')
# DICTIONARY
words = [word for sentence in tiny_corpus_lowered_tokenized for word in sentence]
print(sorted(words),'n')
unique_words = list(set(words))
# ASIGN TO DICTIONARY
id2word = {nr: word for nr, word in enumerate(unique_words)}
print(id2word,'n')
word2id = {word: id for id, word in id2word.items()}
print(word2id,'n')
# ONE HOT ENCODING
from pprint import pprint
import numpy as np
num_word = len(unique_words)
word2one_hot = dict()
for i in range(num_word):
zero_vec = np.zeros(num_word)
zero_vec[i] = 1
word2one_hot[id2word[i]] = list(zero_vec)
# RESULT
pprint(word2one_hot)
Marcin Lewek
Marketing Manager
edrone
Digital marketer and copywriter experienced and specialized in AI, design, and digital marketing itself. Science, and holistic approach enthusiast, after-hours musician, and sometimes actor. LinkedIn
Do you want to increase sales and build even better relationships with your customers?