
Spis treści
Zobacz edrone od środka
Poznaj funkcje, dzięki którym zwiększysz sprzedaż i wzmocnisz relacje z klientami
Word2vec to metoda uczenia maszynowego mająca na celu stworzenie modelu językowego opartego na idei głębokiego uczenia (Deep Learning), jednakże sieć neuronowa wykorzystywana w tym przypadku jest stosunkowo płytka (w jej skład wchodzi zaledwie jedna warstwa ukryta).
Głównym celem tego artykułu jest przekonanie czytelnika, że przetwarzanie języka naturalnego nie jest aż takie trudne – word2vec to takie „Hello world” w obszarze NLP. Wymaga jednak nieco więcej pracy niż napisanie linijki kodu.
- Jak działa word2vec i skąd w ogóle wziął się ten pomysł.
- Jak samodzielnie stworzyć uproszczoną wersję word2vec.
- Jak wykorzystać prostego word2veca do całkiem ciekawych rzeczy.
Zanim zaczniemy…
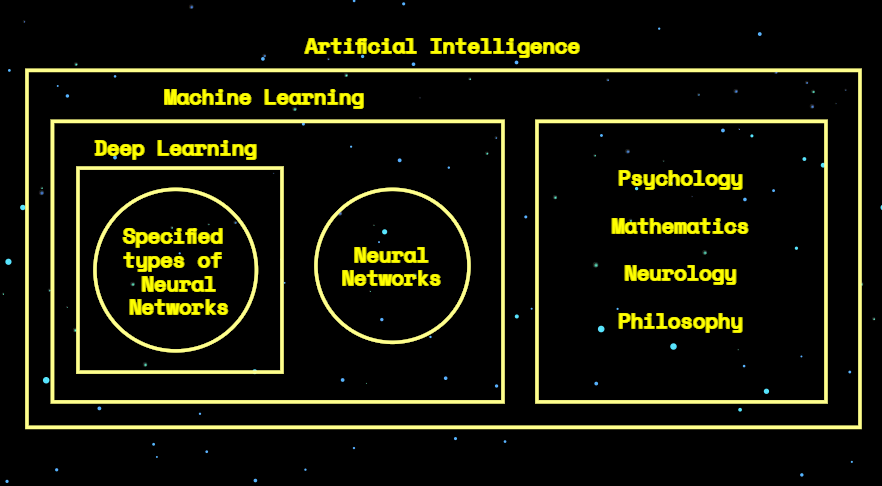
Znajomość wszystkich różnic między sztuczną inteligencją (Artificial Intelligence), uczeniem maszynowym (Machine Learning), a głębokim uczeniem (Deep Learning) nie jest konieczne do zrozumienia tekstu. Jednakże, te terminy są często stosowane zamiennie, co w większości przypadków będzie błędem:
- Deep Learning dotyczy konkretnych typów sieci neuronowych (głębokie sieci wielowarstwowe lub płytkie, ale posiadające liczne wejścia i zależności między poszczególnymi neuronami).
- Deep Learning to sub-dziedzina Machine Learning.
- Machine Learning to sub-dziedzina Artificial Intelligence.
Skoro wszystko jest jasne, podkreślmy: naszym celem jest wykorzystanie metod uczenia maszynowego do budowania modeli językowych w oparciu o idee głębokiego uczenia.
Word2vec – trochę historii
Pierwszy okres wzmożonego zainteresowania uczeniem maszynowym przypada na lata 2005–2012. Kolejny boom, czasami określany mianem rewolucji głębokiego uczenia, rozpoczął się w 2012. Następny ważny etap to opracowanie Word2Vec (i jego klonów: Doc2Vec oraz Nodes2Vec), co miało miejsce w latach 2013–2015. Ostatnim ważnym wydarzeniem było opracowanie techniki BERT (oraz jego klonów: GPT i T5). Okres ten rozpoczął się w 2017 i można śmiało powiedzieć, że trwa do dziś.
Przeczytaj także:
- Chatbot dla e-commerce: różne rodzaje i korzyści
- Automatyczne rozpoznawanie mowy: podstawy, które warto znać
- Nowe możliwości sprzedaży. Wpływ TikToka na e-commerce
Zobacz case study:
Word2Vec to technika przetwarzania języka naturalnego oparta na hipotezie zapostulowanej przez Johna Ruperta Firtha pod koniec lat 50. Zgodnie z nią, każdy wyraz jest charakteryzowany i w pewnym sensie definiowany na podstawie innych wyrazów znajdujących się w jego otoczeniu.
Hipoteza dystrybucyjna
Firth oparł swoją teorię na założeniach Zelliga Harrisa z roku 1954, który twierdził, że wyrazy, występujące w tym samym kontekście, zazwyczaj mają to samo znaczenie. Jeśli się nad tym zastanowić… okazuje się że to jak najbardziej trafne spostrzeżenie!
Hipoteza dystrybucyjna jest podstawą semantyki statystycznej i budzi coraz większe zainteresowanie przedstawicieli kognitywistyki oraz uczenia maszynowego, mimo, że wywodzi się z językoznawstwa.
Kolokacje wyrazów w korpusie tekstu, czyli podstawy semantyki komputerowej
Podsumowując, im więcej identycznych słów pojawia się w kontekście dwóch wybranych wyrazów, tym bliższe są one znaczeniowo. W tym wypadku kontekst jest kwestią umowną. Może to być to samo zdanie, akapit czy, jeśli mówimy o NLP, ta sama ramka, której używamy do analizy korpusu.
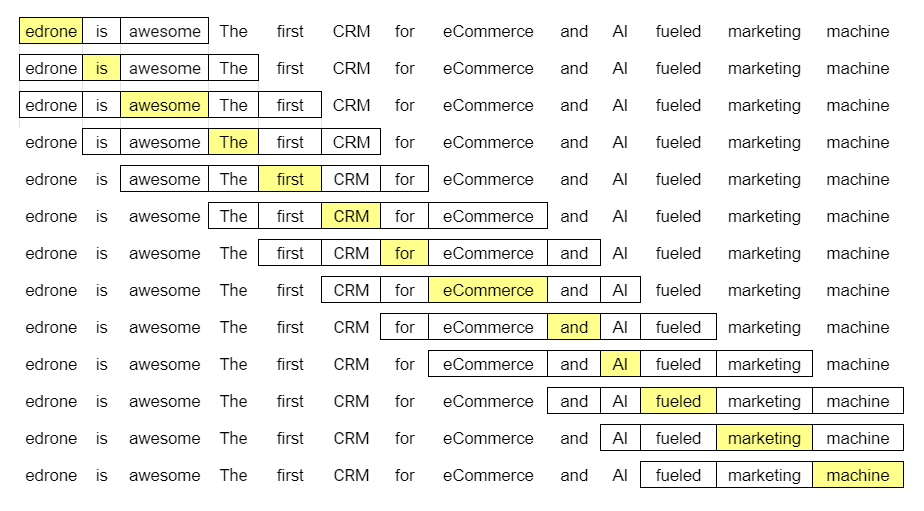
Jak się pewnie domyślasz, im dłuższy tekst, tym precyzyjniejsze przewidywanie słowa na podstawie jego otoczenia. Rozmiar ramki również ma znaczenie, ale wybór w tym przypadku należy do analityka. Większa nie zawsze będzie lepsza.
Gdzie powinniśmy zacząć? Po pierwsze korpus tekstowy musi być zrozumiały dla komputera. Jak się za to zabrać? Nazwa omawianej techniki, jest tutaj podpowiedzią – będziemy zamieniać słowa na wektory.
Postaw na rozwój. Dołącz do ponad 1000 sklepów, które budują swój sukces razem z nami.
Preprocessing
Przykłady są zawsze najlepsze, dlatego poszczególne kroki zaprezentuję w praktyce.
Będziemy korzystać z Pythona. Jeśli pracowałeś z tym językiem, z pewnością masz już gotowe środowisko. Zaprezentowany kod nie wymaga instalacji żadnych dodatkowych bibliotek ponad te, które już posiadasz.
Jeśli nie miałeś styczności z Pythonem, nie martw się. Instalacja jest całkiem prosta. W roli środowiska programistycznego występuje Spyder, ale to po prostu mój subiektywny wybór. Pod koniec tekstu znajdziesz cały kod wykorzystywany w tej części.
Nie przejmuj się, jeśli poszczególne linijki będą nieco tajemnicze, skup się przede wszystkim na wynikach.
Stwórzmy korpus!
Mamy zatem dwa proste zdania. Utwórzmy z nimi korpus i wyświetlmy na ekranie:
edrone is awesome. The first CRM for eCommerce and AI fueled marketing machine.
Kod:
tiny_corpus = ['edrone is awesome',
'The first CRM for eCommerce and AI fueled marketing machine']
print(tiny_corpus,'n')Otrzymujemy:
['edrone is awesome',
'The first CRM for eCommerce and AI fueled marketing machine'] Wielkość liter ma znaczenie, dlatego zamieńmy wszystkie na małe, aby uniknąć duplikatów w słowniku. W tym konkretnym malutkim przykładzie nie jest to istotne, ale w trakcie analizy większych korpusów, już tak. Dodatkowo, na każdym etapie będziemy wyświetlać jego stan aby śledzić dokładnie to, co z nim się dzieje.
Kod:
# LOWER CASE
tiny_corpus_lowered = [sentence.lower() for sentence in tiny_corpus]
print(tiny_corpus_lowered,'n')Otrzymujemy:
['edrone is awesome',
'the first crm for ecommerce and ai fueled marketing machine'] Teraz dzielimy całe zdania na pojedyncze wyrazy.
# TOKENIZATION
tiny_corpus_lowered_tokenized = [sentence.split() for sentence in tiny_corpus_lowered]
print(tiny_corpus_lowered_tokenized,'n')[['edrone', 'is', 'awesome'],
['the', 'first', 'crm', 'for', 'ecommerce', 'and', 'ai', 'fueled', 'marketing', 'machine']]W tym momencie preprocessing jest już prawie gotowy. Stwórzmy słownik do naszego korpusu. W tym celu najpierw zadeklarujemy listę wyrazów z tekstu w porządku alfabetycznym.
# DICTIONARY
words = [word for sentence in tiny_corpus_lowered_tokenized for word in sentence]
print(sorted(words),'n')
unique_words = list(set(words))['ai', 'and', 'awesome', 'crm', 'ecommerce', 'edrone',
'first', 'for', 'fueled', 'is', 'machine', 'marketing', 'the'] A teraz faktyczny słownik. Preprocessing jest skończony!
# ASIGN TO DICTIONARY
id2word = {nr: word for nr, word in enumerate(unique_words)}
print(id2word,'n')
word2id = {word: id for id, word in id2word.items()}
print(word2id,'n'){0: 'is', 1: 'ai', 2: 'first', 3: 'ecommerce', 4: 'the',
5: 'fueled', 6: 'machine', 7: 'for', 8: 'awesome',
9: 'and', 10: 'marketing', 11: 'crm', 12: 'edrone'}
{'is': 0, 'ai': 1, 'first': 2, 'ecommerce': 3, 'the': 4,
'fueled': 5, 'machine': 6, 'for': 7, 'awesome': 8,
'and': 9, 'marketing': 10, 'crm': 11, 'edrone': 12} One-Hot Encoding
Teraz każdemu wyrazowi z listy należy przypisać wektor. Zróbmy to, a następnie omówimy wyniki.
# ONE HOT ENCODING
from pprint import pprint
import numpy as np
num_word = len(unique_words)
word2one_hot = dict()
for i in range(num_word):
zero_vec = np.zeros(num_word)
zero_vec[i] = 1
word2one_hot[id2word[i]] = list(zero_vec)
# RESULT
pprint(word2one_hot)Gotowe. Zamieniliśmy słowa na wektory.
{'ai':
[0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
'and':
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0],
'awesome':
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0],
'crm':
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0],
'ecommerce':
[0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
'edrone':
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0],
'first':
[0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
'for':
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0],
'fueled':
[0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
'is':
[1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
'machine':
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
'marketing':
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0],
'the':
[0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]}Jak widzisz, każdy wyraz pojawiający się w tekście, otrzymał swój własny wektor. Różnią się ona nieco od tych, które możesz pamiętać z lekcji fizyki. Próby wyobrażenia sobie takiego wektora nie mają sensu bo każdy z nich zanurzony jest w 13-wymiarowej przestrzeni. Na szczęście nie musisz tego robić! Zauważ tylko, że:
- Każdy wymiar reprezentuje kolejny wyraz w tekście.
- Każdy wektor składa się z kilkunastu zer i jednej jedynki.
- Każda jedynka pojawia się w pozycji innego parametru wektora.
Gdyby nasz tekst składał się ze 100 różnych wyrazów, na każdy wektor składałoby się 99 zer i jedna jedynka, za każdym razem w innej pozycji. Ta konwencja pozwala na stosunkowo proste przetwarzanie wyrazów. Jak przetwarzane są wektory? Tego dowiecie się w części 2.!
Cały kod, dla Twojego użytku:
tiny_corpus = ['edrone is awesome',
'The first CRM for eCommerce and AI fueled marketing machine']
print(tiny_corpus,'n')
# LOWER CASE
tiny_corpus_lowered = [sentence.lower() for sentence in tiny_corpus]
print(tiny_corpus_lowered,'n')
# TOKENIZATION
tiny_corpus_lowered_tokenized = [sentence.split() for sentence in tiny_corpus_lowered]
print(tiny_corpus_lowered_tokenized,'n')
# DICTIONARY
words = [word for sentence in tiny_corpus_lowered_tokenized for word in sentence]
print(sorted(words),'n')
unique_words = list(set(words))
# ASIGN TO DICTIONARY
id2word = {nr: word for nr, word in enumerate(unique_words)}
print(id2word,'n')
word2id = {word: id for id, word in id2word.items()}
print(word2id,'n')
# ONE HOT ENCODING
from pprint import pprint
import numpy as np
num_word = len(unique_words)
word2one_hot = dict()
for i in range(num_word):
zero_vec = np.zeros(num_word)
zero_vec[i] = 1
word2one_hot[id2word[i]] = list(zero_vec)
# RESULT
pprint(word2one_hot)
Chcesz dowiedzieć się więcej o wykorzystaniu mowy naturalnej?

Marcin Lewek
Marketing Manager
edrone
Wychodzi z założenia, że wszechstronność w życiu jest najważniejsza, dlatego w dzieciństwie chciał zostać paleontologiem, studiował fizykę, a został marketerem. W edrone dba o właściwą ekspozycję marki w analogowo-cyfrowej przestrzeni, automatyzacje, i przepływ informacji. Dodatkowo eksploruje sztuczną inteligencję z ramienia marketingu i projektuje treści pozwalające ludziom zrozumieć i oswoić się ze AI jako narzędziem obecnym w codziennym życiu – nie tylko zawodowym. LinkedIn
Zobacz edrone od środka
Poznaj funkcje, dzięki którym zwiększysz sprzedaż i wzmocnisz relacje z klientami