
Concordância entre Anotadores: A Linguagem em Disputa
Índice

CRM e Automação de Marketing Gratuitos
Comece a usar a edrone sem pagar nada e deixe o seu e-commerce no piloto automático!
Quando o assunto é Processamento de Linguagem Natural e o desenvolvimento de assistentes por voz, mais cedo ou mais tarde você encontrará o termo “concordância entre anotadores”. Este acordo é fundamental para atingirmos a ilusão de que as máquinas estão, de fato, entendendo palavras.
A linguagem sempre permitiu que os humanos se comunicassem e cooperassem em prol de um bem comum. Esta cooperação e transmissão de conhecimentos adquiridos ao longo do tempo foram possibilitadas por um acordo não inteiramente consciente. Até aí tudo bem, mas parece que chegou a hora de redefinirmos este acordo devido à Inteligência Artificial (ou graças à ela).
Via de regra, vale a pena almejar um acordo, certo? É possível listar milhares de razões para isso, começando pela satisfação pessoal e chegando até a paz mundial. Porém, embora discutir se algo é branco ou preto seja algo relativamente fácil e objetivo, certos aspectos da nossa existência podem ser – para usar um termo suave – discutíveis.
Como você pode imaginar, a própria comunicação oral é uma destas coisas discutíveis, pois não há definições objetivas de “certo” e “errado”. Isso faz com que os computadores tenham dificuldade em processá-la, apenas mais uma demonstração de que a complexidade da evolução humana não pode ser subestimada.
Ao longo de milhares de gerações, o ser humano tem exercitado a comunicação oral, o processo de compartilhar pensamentos através da fala, o que resultou em um excelente domínio sobre a linguagem. No entanto, embora o significado das palavras geralmente seja claro para a maioria de nós, classificá-las é uma tarefa muito mais desafiadora!

Um dia como qualquer outro no projeto AVA. Mas vamos começar do começo.
Vamos parametrizar os termos
A Inteligência Artificial pode ir fundo em qualquer tarefa que a dermos, mas é preciso definir limites razoáveis. Quando lidamos com Processamento de Linguagem Natural (PLN), um destes limites são as anotações.
O que é uma anotação? Em poucas palavras, é a classificação de um termo ou, mais precisamente, sua parametrização. Podemos pensar nas anotações como limites ou “linhas-guia” para o PLN.
Outro conceito que precisa ser destacado é o corpus. Este é o texto (geralmente longo) que informaremos como dado de entrada (input) para o algoritmo processar e nos fornecer os resultados.
Aposte no conhecimento para desenvolver o seu negócio!
Envolvimento humano: Human in the Loop
Quem faz as anotações nos corpus enormes é o anotador. Temos um corpus de texto e queremos etiquetar as palavras, mas não todas elas. A ideia é que a AVA possa automatizar este processo o máximo possível, então precisamos ensinar o sistema a fazer as anotações por conta própria. Isso exige fazer algumas anotações manualmente.
As etiquetas dependem do que exatamente nós desejamos obter do algoritmo, e quais aspectos do corpus ele analisará. No nosso caso, queremos que ele determine “o que é, e o que não é, um atributo de produto”.
Como você pode ter percebido, tudo “depende”, “é questão de escolha”, “varia conforme o objetivo desejado”. O Aprendizado de Máquina (Machine Learning), em geral, envolve definir o escopo concreto do projeto, fornecer os dados corretos à Rede Neural, verificar e fazer ajustes, acompanhando se determinados inputs geram os outputs desejados. No entanto, embora possa parecer que há um “fantasma na máquina”, não tem mágica aqui.
É preciso discutir
O projeto AVA, assim como a edrone como um todo, foca estritamente em eCommerce, consequentemente lidando com produtos e suas características. Estas características podem ser descritas de alguma maneira (tamanho, cor, material etc). Sendo assim, a tarefa de fazer as anotações parece ser simples, já que é apenas uma questão de identificar os atributos de cada produto e descrevê-los!
Então nosso corpus será uma lista de produtos com suas descrições, fichas técnicas, medidas etc, para auxiliar os consumidores quando buscarem pelos produtos que desejam. No entanto, precisamos fazer um pequeno teste para nos assegurarmos de que a equipe de anotadores está em sintonia.
Por que isso é tão importante? Porque precisamos ensinar o algoritmo a anotar cada atributo corretamente. A concordância entre anotadores se traduzirá posteriormente na eficiência do algoritmo, que foi testado pela equipe.
É preciso concordar
Quando se fala em avaliar a eficiência de avaliações sim/não, é muito comum encontrar o termo “F-score” ou “F1-score”. Pode parecer um pouco complicado no começo, mas acredite, é brincadeira de criança (ok, talvez de adolescente). Tudo se resume a somar, multiplicar e dividir alguns valores.
F1-score
Temos dois anotadores que farão as anotações no corpus individual e secretamente. O F1-score exige um ponto de referência, portanto um dos anotadores será considerado “arbitrariamente certo”.
Este anotador de referência definirá a divisão de “atributos/não atributos” (respectivamente, lado esquerdo e direito da imagem abaixo). O outro anotador será testado em relação ao primeiro (suas escolhas estão dentro do círculo na imagem abaixo).
Esta palavra representa um atributo do produto?
- Verdadeiro positivo: A resposta foi “Sim”, e trata-se de um atributo do produto.
- Verdadeiro negativo: A resposta foi “Não”, e de fato não é um atributo do produto.
- Falso positivo: A resposta foi “Sim”, mas aquele não é um atributo do produto.
- Falso negativo: A resposta foi “Não”, mas aquele é um atributo do produto.
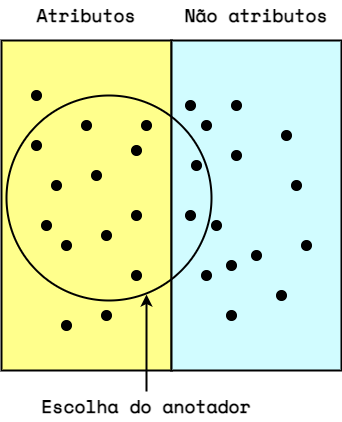
Portanto, no exemplo acima temos:
Verdadeiro Positivo = 11
Verdadeiro Negativo = 13
Falso Positivo = 2
Falso Negativo = 3Bem simples até aqui, certo? Agora vamos complicar um pouco e calcular a precisão e revocação das anotações.
Podemos dizer que a precisão foca nas respostas “sim” (VP e FP). Ela responde à pergunta: Qual parcela dos atributos selecionados (dentro do círculo) eram, de fato, atributos do produto?
[ {displaystyle text{Precisão} = {frac {text{VP}}{text{VP}+text{FP}}} = {frac {11}{13}} = 0.846 !} ]
A revocação, por outro lado, considera todos os atributos. Ela responde à pergunta: Qual parcela de atributos relevantes foi selecionada?
[ {displaystyle text{Revocação} = {frac {text{VP}}{text{VP}+text{FN}}} = {frac {11}{14}} = 0.785 !} ]
Agora calculamos o F1-score:
[ {displaystyle text{F1} = { 2 cdot frac {text{Precisão} cdot text{Revocação}}{text{Precisão}+text{Revocação}}} = 0.814 !} ]
Nada mal! Infelizmente, este é apenas um exemplo inventado. A vida real não é assim tão fácil 😉
Coeficiente kappa de Cohen
O F1-score não reflete a concordância de fato, uma vez que não leva em consideração a probabilidade dela acontecer. Hora de complicar um pouco mais com a introdução de uma letrinha grega: 𝜅, ou kappa. No contexto da estatística, temos duas variações de kappa:
- Kappa de Cohen: usado quando dois anotadores fazem anotações de atributos de uma mesma categoria.
- Kappa de Fleiss: usado quando mais de dois anotadores fazem anotações de atributos de uma mesma categoria 𝑛 vezes.
Além de considerar a probabilidade das concordâncias, o kappa também permite compararmos as taxas de concordância entre testes diferentes. Por exemplo, o coeficiente 𝜅 de anotações em forma de palavras pode ser comparado ao 𝜅 de anotações de imagens.
O kappa de Cohen representa o exemplo apresentado acima, portanto é o que usaremos para avançar.
[ {displaystyle kappa equiv {frac {p_{o}-p_{e}}{1-p_{e}}}!} ]
[ p_0 – text{taxa de concordância relativa} ]
O Kappa de Cohen leva em consideração a probabilidade da concordância acontecer aleatoriamente.
[ p_e – text{probabilidade de concordância aleatória} ]
[ p_e = p_{sim}+p_{não} ]
[ p_{sim} – text{probabilidade de concordância positiva (SIM)} newline p_{não} – text{probabilidade de concordância negativa (NÃO)} ]
Probabilidade de concordância positiva (SIM): Comparativo entre a proporção de respostas “sim” do anotador A com a proporção de respostas “sim” do anotador B:
[ {displaystyle p_{sim} = {frac {S_{A}}{S_{A}+N_{A}}} cdot {frac {S_{B}}{S_{B}+N_{B}}}!} ]
Probabilidade de concordância negativa (NÃO): Comparativo entre a proporção de respostas “não” do anotador A com a proporção de respostas “não” do anotador B:
[ {displaystyle p_{não} = {frac {N_{A}}{S_{A}+N_{A}}} cdot {frac {N_{B}}{S_{B}+N_{B}}}!} ]
O coeficiente kappa de Cohen pode ter valores entre -1 e 1. Porém, valores negativos de kappa devem ser descartados e reavaliados.
Um coeficiente kappa negativo indica que os anotadores estão em discordância em vez de concordância. Em outras palavras, as anotações seriam mais compatíveis entre si se fossem aleatórias.
Por isso, na prática, lidamos apenas com valores positivos de kappa.
| Coeficiente Kappa | Concordância | % de dados confiáveis |
|---|---|---|
| 0.00 – 0.20 | Insignificante | 0 – 4% |
| 0.21 – 0.39 | Mínima | 4 – 15% |
| 0.40 – 0.59 | Fraca | 15 – 35% |
| 0.60 – 0.79 | Moderada | 35 – 63% |
| 0.80 – 0.90 | Forte | 64 – 81% |
| 0.91 – 1.00 | Quase perfeita | 82 – 100% |
Agende uma demonstração gratuita e ganhe 5% de desconto no seu plano anual.
Concordância entre Anotadores na prática
Em um teste real que fizemos no desenvolvimento da AVA, escolhemos quatro eCommerces e selecionamos cinco produtos aleatórios de cada loja, totalizando 20 produtos. A tarefa era identificar corretamente os nomes (p. ex. “cor”), valores (p. ex. “azul”), e outras descrições de seus atributos.
Para extrair o máximo possível de informações, este teste envolveu três anotadores que são especialistas em Inteligência Artificial (vamos chamá-los de Lucas, Humberto e Pedro), em três cenários. Os anotadores trabalharam em pares, gerando três resultados para cada cenário. Os F1-scores também foram calculados.
Cenário I – [ALL] – cinco parâmetros
- Nome – início
- Nome – meio
- Valor – início
- Valor – meio
- Outros
Cenário II – [ATR] – três parâmetros
- Nome
- Valor
- Outros
Cenário III – [NAM] – três parâmetros
- Nome – início
- Nome – meio
- Outros
Nos cenários I e III há uma divisão dos nomes e valores entre “início” e “meio”. Isso não é crucial para compreender este artigo, mas vale a pena ser mencionado. Os nomes e valores de cada atributo são compostos por unidades mínimas de anotação chamadas de “tokens”. O token pode ser uma palavra, um conjunto de palavras, um conjunto de letras, ou apenas uma letra. Sua definição é uma escolha de quem está conduzindo o experimento. O “início” é o primeiro token, e o “meio” é todo o restante.
Como tivemos três pares de anotadores trabalhando em três cenários, cada um gerando duas métricas (F1-score e coeficiente kappa), o experimento gerou um total de 18 métricas que podemos usar para avaliar a concordância entre anotadores:
| Cenário ALL | ||
|---|---|---|
| Anotadores | F1-score | Kappa de Cohen |
| (H, L) | 0.5359 | 0.4679 |
| (H, P) | 0.5509 | 0.4974 |
| (L, P) | 0.5960 | 0.5674 |
| Cenário ATR | ||
|---|---|---|
| Anotadores | F1-score | Kappa de Cohen |
| (H, L) | 0.6548 | 0.4918 |
| (H, P) | 0.6767 | 0.5284 |
| (L, P) | 0.7031 | 0.5918 |
| Cenário NAM | ||
|---|---|---|
| Anotadores | F1-score | Kappa de Cohen |
| (H, L) | 0.6017 | 0.4639 |
| (H, P) | 0.6292 | 0.5132 |
| (L, P) | 0.6552 | 0.5239 |
Estes resultados são bons? Não muito. O nível de concordância foi fraco. Isso é ruim? Não necessariamente! Resultados abaixo do esperado faz parte de qualquer processo de P&D. Porém, os resultados nos dão pistas, e o importante é saber interpretá-los para continuar avançando.
É preciso ter perspectiva
Os resultados representam o ponto de vista de cada anotador. Basicamente, significa que eles têm opiniões diferentes sobre quais deveriam ser os nomes dos atributos e quais valores devem identificá-los. O que podemos aprender com isso?
Eficiência do anotador
Precisamos ensinar o algoritmo a fazer as anotações de cada atributo corretamente. A concordância entre anotadores determinará a eficiência (medida pelo F1-score) com a qual o algoritmo conseguirá fazer isso.
Se o ponto de referência para o F1-score for determinado pelas anotações do Lucas, o algoritmo aprenderá a fazer anotações da mesma forma que o Lucas faz. Neste caso, a concordância entre o Lucas e o algoritmo será alta. Porém, se testarmos este algoritmo contra o Humberto, a taxa de concordância entre os anotadores terá um valor semelhante ao do teste Lucas vs. Humberto.
Como fazer anotações de forma correta
Em todos os cenários, os testes Lucas vs. Pedro tiveram os maiores valores de concordância. Isto aponta que uma abordagem semelhante à deles pode ser o melhor caminho. Por outro lado, vale analisar o que tinha de diferente na abordagem de Humberto, pois ele pode estar considerando ou percebendo algum detalhe interessante, e no fim pode ser que a abordagem dele seja a melhor.
Mantenha a calma, faça anotações e calcule o kappa. Temos uma Inteligência Artificial para construir!

Pedro Paranhos
Margeting manager
edrone
Marketing Manager LATAM at edrone. Full-stack marketer interested in technology, history (and thus, the future), business and languages. Bookworm and craft beer enthusiast.
CRM e Automação de Marketing Gratuitos
Comece a usar a edrone sem pagar nada e deixe o seu e-commerce no piloto automático!


