
Tabla de contenido
Cuando se trata de Procesamiento de Lenguaje Natural y el desarrollo de asistentes de voz, tarde o temprano encontrarás el término “concordancia entre anotadores”. Este acuerdo es fundamental para lograr la ilusión de que las máquinas están, de hecho, entendiendo palabras.
El lenguaje siempre ha permitido que los humanos se comuniquen y cooperen en pro de un bien común. Esta cooperación y transmisión de conocimientos adquiridos a lo largo del tiempo fueron posibilitadas por un acuerdo no del todo consciente. Hasta ahí todo bien, pero parece que ha llegado el momento de redefinir este acuerdo debido a la Inteligencia Artificial (o gracias a ella).
Por regla general, vale la pena aspirar a un acuerdo, ¿cierto? Es posible enumerar miles de razones para ello, comenzando por la satisfacción personal y llegando hasta la paz mundial. Sin embargo, aunque discutir si algo es blanco o negro sea algo relativamente fácil y objetivo, ciertos aspectos de nuestra existencia pueden ser – para usar un término suave – discutibles.
Como puedes imaginar, la propia comunicación oral es una de estas cosas discutibles, ya que no hay definiciones objetivas de “correcto” e “incorrecto”. Esto hace que las computadoras tengan dificultad en procesarla, solo una demostración más de que la complejidad de la evolución humana no puede ser subestimada.
A lo largo de miles de generaciones, el ser humano ha ejercitado la comunicación oral, el proceso de compartir pensamientos a través del habla, lo que resultó en un excelente dominio del lenguaje. Sin embargo, aunque el significado de las palabras generalmente sea claro para la mayoría de nosotros, clasificarlas es una tarea mucho más desafiante!

Un día como cualquier otro en el proyecto AVA. Pero empecemos desde el principio.
Vamos a parametrizar los términos
La Inteligencia Artificial puede profundizar en cualquier tarea que le demos, pero es necesario definir límites razonables. Cuando tratamos con Procesamiento de Lenguaje Natural (PLN), uno de estos límites son las anotaciones.
¿Qué es una anotación? En pocas palabras, es la clasificación de un término o, más precisamente, su parametrización. Podemos pensar en las anotaciones como límites o “líneas guía” para el PLN.
Otro concepto que necesita ser destacado es el corpus. Este es el texto (generalmente largo) que informaremos como dato de entrada (input) para que el algoritmo procese y nos proporcione los resultados.
¡Apuesta en el conocimiento para desarrollar tu negocio!
Involucramiento humano: Human in the Loop
Quien hace las anotaciones en los enormes corpus es el anotador. Tenemos un corpus de texto y queremos etiquetar las palabras, pero no todas ellas. La idea es que AVA pueda automatizar este proceso lo máximo posible, así que necesitamos enseñar al sistema a hacer las anotaciones por su cuenta. Esto requiere hacer algunas anotaciones manualmente.
Las etiquetas dependen de lo que exactamente deseamos obtener del algoritmo, y qué aspectos del corpus analizará. En nuestro caso, queremos que determine “qué es, y qué no es, un atributo de producto”.
Como puedes haber notado, todo “depende”, “es cuestión de elección”, “varía según el objetivo deseado”. El Aprendizaje Automático (Machine Learning), en general, implica definir el alcance concreto del proyecto, proporcionar los datos correctos a la Red Neuronal, verificar y hacer ajustes, siguiendo si determinados inputs generan los outputs deseados. Sin embargo, aunque pueda parecer que hay un “fantasma en la máquina”, no hay magia aquí.
Es necesario discutir
El proyecto AVA, al igual que edrone en su totalidad, se centra estrictamente en eCommerce, lidiando consecuentemente con productos y sus características. Estas características pueden ser descritas de alguna manera (tamaño, color, material, etc.). Así, la tarea de hacer las anotaciones parece ser simple, ya que es solo cuestión de identificar los atributos de cada producto y describirlos!
Entonces nuestro corpus será una lista de productos con sus descripciones, fichas técnicas, medidas, etc., para ayudar a los consumidores cuando busquen los productos que desean. Sin embargo, necesitamos hacer una pequeña prueba para asegurarnos de que el equipo de anotadores esté en sintonía.
¿Por qué es esto tan importante? Porque necesitamos enseñar al algoritmo a anotar cada atributo correctamente. La concordancia entre anotadores se traducirá posteriormente en la eficiencia del algoritmo, que ha sido probado por el equipo.
Es necesario concordar
Cuando se habla de evaluar la eficiencia de evaluaciones sí/no, es muy común encontrar el término “F-score” o “F1-score”. Puede parecer un poco complicado al principio, pero créeme, es un juego de niños (bueno, tal vez de adolescentes). Todo se reduce a sumar, multiplicar y dividir algunos valores.
F1-score
Tenemos dos anotadores que harán las anotaciones en el corpus de manera individual y secreta. El F1-score requiere un punto de referencia, por lo que uno de los anotadores será considerado “arbitrariamente correcto”.
Este anotador de referencia definirá la división de “atributos/no atributos” (respectivamente, lado izquierdo y derecho de la imagen a continuación). El otro anotador será probado en relación al primero (sus elecciones están dentro del círculo en la imagen a continuación).
¿Esta palabra representa un atributo del producto?
- Verdadero positivo: La respuesta fue “Sí”, y se trata de un atributo del producto.
- Verdadero negativo: La respuesta fue “No”, y de hecho no es un atributo del producto.
- Falso positivo: La respuesta fue “Sí”, pero ese no es un atributo del producto.
- Falso negativo: La respuesta fue “No”, pero ese es un atributo del producto.
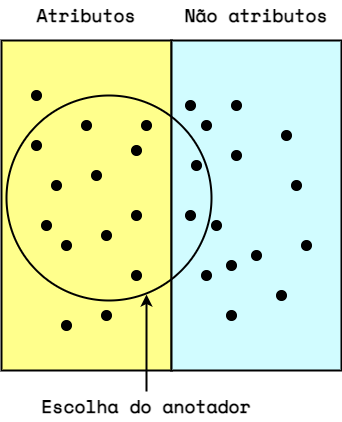
Por lo tanto, en el ejemplo anterior tenemos:
Verdadero Positivo = 11
Verdadero Negativo = 13
Falso Positivo = 2
Falso Negativo = 3Bien simple hasta aquí, ¿cierto? Ahora vamos a complicar un poco y calcular la precisión y revocación de las anotaciones.
Podemos decir que la precisión se centra en las respuestas “sí” (VP y FP). Responde a la pregunta: ¿Qué parte de los atributos seleccionados (dentro del círculo) eran, de hecho, atributos del producto?
[ {displaystyle text{Precisión} = {frac {text{VP}}{text{VP}+text{FP}}} = {frac {11}{13}} = 0.846 !} ]
La revocación, por otro lado, considera todos los atributos. Responde a la pregunta: ¿Qué parte de atributos relevantes fue seleccionada?
[ {displaystyle text{Revocación} = {frac {text{VP}}{text{VP}+text{FN}}} = {frac {11}{14}} = 0.785 !} ]
Ahora calculamos el F1-score:
[ {displaystyle text{F1} = { 2 cdot frac {text{Precisión} cdot text{Revocación}}{text{Precisión}+text{Revocación}}} = 0.814 !} ]
¡Nada mal! Desafortunadamente, este es solo un ejemplo inventado. La vida real no es tan fácil 😉
Coeficiente kappa de Cohen
El F1-score no refleja la concordancia de hecho, ya que no toma en cuenta la probabilidad de que ocurra. Hora de complicar un poco más con la introducción de una letra griega: 𝜅, o kappa. En el contexto de la estadística, tenemos dos variaciones de kappa:
- Kappa de Cohen: usado cuando dos anotadores hacen anotaciones de atributos de una misma categoría.
- Kappa de Fleiss: usado cuando más de dos anotadores hacen anotaciones de atributos de una misma categoría 𝑛 veces.
Además de considerar la probabilidad de las concordancias, el kappa también permite comparar las tasas de concordancia entre pruebas diferentes. Por ejemplo, el coeficiente 𝜅 de anotaciones en forma de palabras puede ser comparado con el 𝜅 de anotaciones de imágenes.
El kappa de Cohen representa el ejemplo presentado arriba, por lo tanto es el que usaremos para avanzar.
[ {displaystyle kappa equiv {frac {p_{o}-p_{e}}{1-p_{e}}}!} ]
[ p_0 – text{tasa de concordancia relativa} ]
El Kappa de Cohen toma en cuenta la probabilidad de que la concordancia ocurra aleatoriamente.
[ p_e – text{probabilidad de concordancia aleatoria} ]
[ p_e = p_{sí}+p_{no} ]
[ p_{sí} – text{probabilidad de concordancia positiva (SÍ)} newline p_{no} – text{probabilidad de concordancia negativa (NO)} ]
Probabilidad de concordancia positiva (SÍ): Comparativo entre la proporción de respuestas “sí” del anotador A con la proporción de respuestas “sí” del anotador B:
[ {displaystyle p_{sí} = {frac {S_{A}}{S_{A}+N_{A}}} cdot {frac {S_{B}}{S_{B}+N_{B}}}!} ]
Probabilidad de concordancia negativa (NO): Comparativo entre la proporción de respuestas “no” del anotador A con la proporción de respuestas “no” del anotador B:
[ {displaystyle p_{no} = {frac {N_{A}}{S_{A}+N_{A}}} cdot {frac {N_{B}}{S_{B}+N_{B}}}!} ]
El coeficiente kappa de Cohen puede tener valores entre -1 y 1. Sin embargo, los valores negativos de kappa deben ser descartados y reevaluados.
Un coeficiente kappa negativo indica que los anotadores están en desacuerdo en lugar de acuerdo. En otras palabras, las anotaciones serían más compatibles entre sí si fueran aleatorias.
Por eso, en la práctica, solo tratamos con valores positivos de kappa.
| Coeficiente Kappa | Concordancia | % de datos confiables |
|---|---|---|
| 0.00 – 0.20 | Insignificante | 0 – 4% |
| 0.21 – 0.39 | Mínima | 4 – 15% |
| 0.40 – 0.59 | Débil | 15 – 35% |
| 0.60 – 0.79 | Moderada | 35 – 63% |
| 0.80 – 0.90 | Fuerte | 64 – 81% |
| 0.91 – 1.00 | Casi perfecta | 82 – 100% |
Agenda una demostración gratuita y gana un 5% de descuento en tu plan anual.rnrn
Concordancia entre Anotadores en la práctica
En una prueba real que hicimos en el desarrollo de AVA, elegimos cuatro eCommerces y seleccionamos cinco productos aleatorios de cada tienda, totalizando 20 productos. La tarea era identificar correctamente los nombres (p. ej. “color”), valores (p. ej. “azul”), y otras descripciones de sus atributos.
Para extraer el máximo posible de información, esta prueba involucró a tres anotadores que son especialistas en Inteligencia Artificial (los llamaremos Lucas, Humberto y Pedro), en tres escenarios. Los anotadores trabajaron en pares, generando tres resultados para cada escenario. Los F1-scores también fueron calculados.
Escenario I – [ALL] – cinco parámetros
- Nombre – inicio
- Nombre – medio
- Valor – inicio
- Valor – medio
- Otros
Escenario II – [ATR] – tres parámetros
- Nombre
- Valor
- Otros
Escenario III – [NAM] – tres parámetros
- Nombre – inicio
- Nombre – medio
- Otros
En los escenarios I y III hay una división de los nombres y valores entre “inicio” y “medio”. Esto no es crucial para comprender este artículo, pero vale la pena mencionarlo. Los nombres y valores de cada atributo están compuestos por unidades mínimas de anotación llamadas “tokens”. El token puede ser una palabra, un conjunto de palabras, un conjunto de letras, o solo una letra. Su definición es una elección de quien está conduciendo el experimento. El “inicio” es el primer token, y el “medio” es todo el resto.
Como tuvimos tres pares de anotadores trabajando en tres escenarios, cada uno generando dos métricas (F1-score y coeficiente kappa), el experimento generó un total de 18 métricas que podemos usar para evaluar la concordancia entre anotadores:
| Escenario ALL | ||
|---|---|---|
| Anotadores | F1-score | Kappa de Cohen |
| (H, L) | 0.5359 | 0.4679 |
| (H, P) | 0.5509 | 0.4974 |
| (L, P) | 0.5960 | 0.5674 |
| Escenario ATR | ||
|---|---|---|
| Anotadores | F1-score | Kappa de Cohen |
| (H, L) | 0.6548 | 0.4918 |
| (H, P) | 0.6767 | 0.5284 |
| (L, P) | 0.7031 | 0.5918 |
| Escenario NAM | ||
|---|---|---|
| Anotadores | F1-score | Kappa de Cohen |
| (H, L) | 0.6017 | 0.4639 |
| (H, P) | 0.6292 | 0.5132 |
| (L, P) | 0.6552 | 0.5239 |
¿Estos resultados son buenos? No mucho. El nivel de concordancia fue débil. ¿Eso es malo? ¡No necesariamente! Resultados por debajo de lo esperado son parte de cualquier proceso de I+D. Sin embargo, los resultados nos dan pistas, y lo importante es saber interpretarlos para seguir avanzando.
Es necesario tener perspectiva
Los resultados representan el punto de vista de cada anotador. Básicamente, significa que tienen opiniones diferentes sobre cuáles deberían ser los nombres de los atributos y qué valores deben identificarlos. ¿Qué podemos aprender de esto?
Eficiência del anotador
Necesitamos enseñar al algoritmo a hacer las anotaciones de cada atributo correctamente. La concordancia entre anotadores determinará la eficiencia (medida por el F1-score) con la cual el algoritmo podrá hacer esto.
Si el punto de referencia para el F1-score es determinado por las anotaciones de Lucas, el algoritmo aprenderá a hacer anotaciones de la misma manera que Lucas lo hace. En este caso, la concordancia entre Lucas y el algoritmo será alta. Sin embargo, si probamos este algoritmo contra Humberto, la tasa de concordancia entre los anotadores tendrá un valor similar al de la prueba Lucas vs. Humberto.
Cómo hacer anotaciones de forma correcta
En todos los escenarios, las pruebas Lucas vs. Pedro tuvieron los mayores valores de concordancia. Esto apunta a que un enfoque similar al de ellos puede ser el mejor camino. Por otro lado, vale la pena analizar qué había de diferente en el enfoque de Humberto, ya que él puede estar considerando o percibiendo algún detalle interesante, y al final puede ser que su enfoque sea el mejor.
Mantén la calma, haz anotaciones y calcula el kappa. ¡Tenemos una Inteligencia Artificial que construir!

Pedro Paranhos
Margeting manager
edrone
Marketing Manager LATAM at edrone. Full-stack marketer interested in technology, history (and thus, the future), business and languages. Bookworm and craft beer enthusiast.